DeepSeek Changed the AI Industry!
A Complete Guide from Tech Innovation to Local Use
Ete and Ran explain everything about China's super-powerful AI "DeepSeek"!
Ran! Ran! This is huge! There's been so much news about "DeepSeek" lately! NVIDIA lost 90 trillion yen in market cap in a single day, and Chinese AI supposedly overtook American AI...
Ete-senpai, please calm down. The "DeepSeek Shock" in January 2025 was indeed a historic event in the AI industry. Its impact continues even now in 2026.
So what exactly IS DeepSeek? Is it different from ChatGPT or Claude? Explain it so even I can understand!
Sure thing. DeepSeek (Deep Search in Chinese) is a generative AI developed by a company based in Hangzhou, China. When "DeepSeek-R1" was released in January 2025, it achieved performance equal to OpenAI's o1 series while being offered at over 100 times lower cost at the time. That was the shock.
What!? Same performance at a fraction of the price!? No wonder everyone's making such a big deal about it...

On January 27, 2025, right after DeepSeek-R1 was released, NVIDIA's stock price crashed about 17-18% in a single day. That's roughly $600 billion in market cap, or about 90 trillion yen, evaporating instantly.
Wait, NVIDIA is that graphics card company, right? What does that have to do with AI?
Great question. Running generative AI like ChatGPT or Claude requires massive amounts of computation. NVIDIA's GPUs (Graphics Processing Units) can handle these calculations at high speed.
*GPU: Originally designed for game graphics processing, but it turned out to be excellent for AI calculations too, making it now an essential component for AI development.
I see, I see. So NVIDIA was making money because you need lots of expensive graphics cards to make AI?
Exactly! Silicon Valley believed that "to improve AI performance, just buy more high-performance GPUs." This was called "Scaling Laws," but...
"But"? What happened?
DeepSeek proved that "with smart algorithms, you can create high-performance AI even with fewer GPUs." Investors thought, "Wait, maybe GPU sales will slow down..." and rushed to sell NVIDIA stock.
I see... So they proved that brains beat brawn—you can win with fewer resources if you're smart about it. How satisfying!

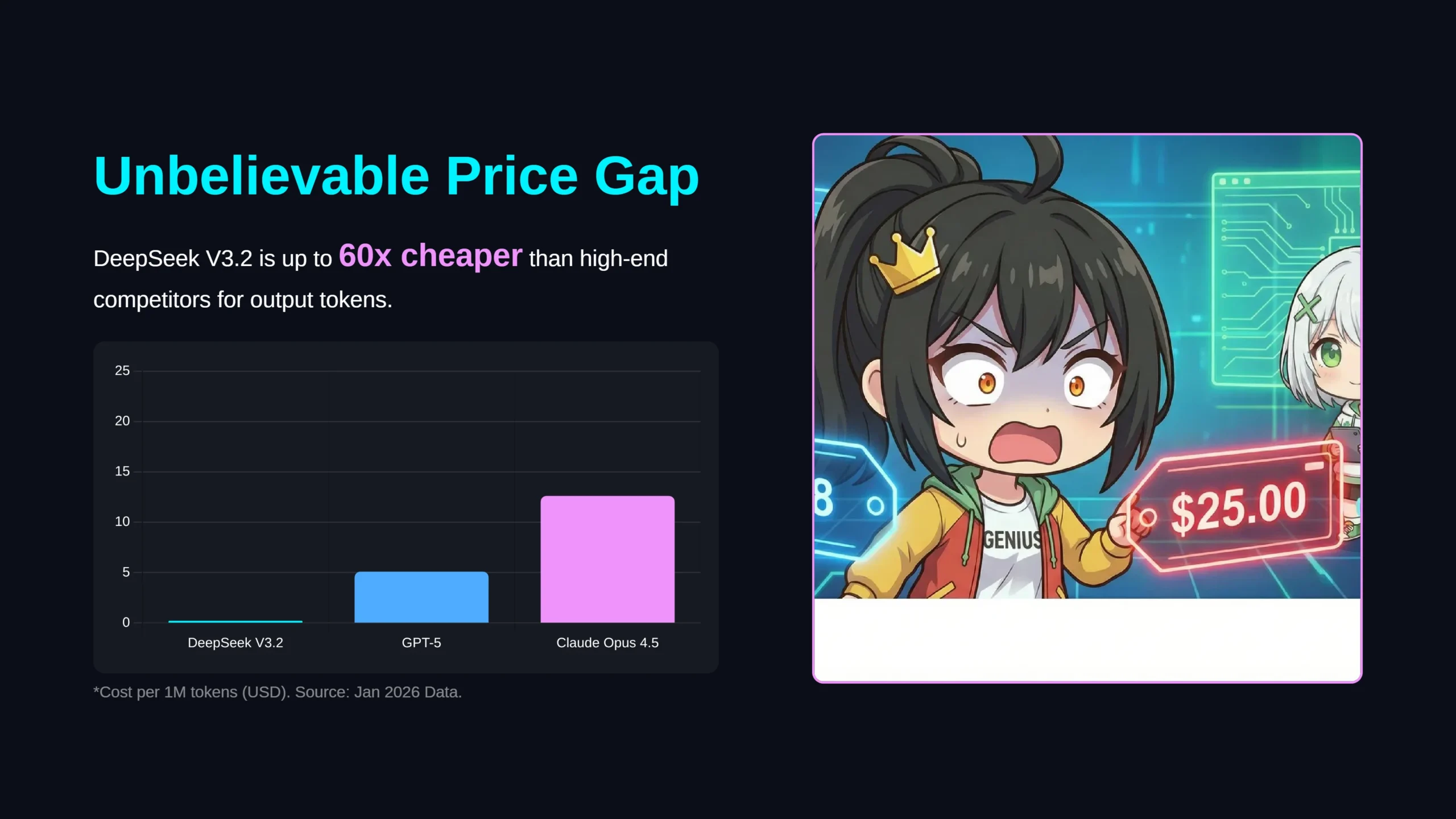
So how much cheaper exactly? Give me some actual numbers!
Let's compare API pricing. Here's the cost per million tokens for all the major flagship models:
*Token: The smallest unit AI uses to process text. One Japanese character equals about 1-2 tokens.
| Model | Input Cost | Output Cost | Notes |
|---|---|---|---|
| DeepSeek R1 | $0.55 | $1.68 | Reasoning |
| DeepSeek V3.2 | $0.28 | $0.42 | General chat |
| OpenAI GPT-5 | $1.25 | $10.00 | Flagship model |
| OpenAI o3 | $2.00 | $8.00 | Reasoning |
| Claude Sonnet 4.5 | $3.00 | $15.00 | Anthropic flagship |
| Claude Opus 4.5 | $5.00 | $25.00 | Top performance |
| Gemini 2.5 Pro | $1.25 | $10.00 | Google flagship |
| Gemini 3 Pro | $2.00 | $12.00 | Latest preview |
*As of January 2026. Price per 1M tokens (USD). Prices are subject to change.
Wait a minute! Claude Opus 4.5 is $5.00 while DeepSeek V3.2 is $0.28!? That's about 18x cheaper for input and 60x cheaper for output!!
Exactly. While the price gap has narrowed since the initial release, DeepSeek still offers the best cost-performance ratio among major models. And it sometimes outscores others on math and programming benchmarks.
That's incredible! Even compared to the most expensive models, DeepSeek is dozens of times cheaper! I totally understand why companies would want to switch to save costs!
By the way, you keep mentioning R1 and V3.2 and all these different things—what's the difference? My head is spinning...
Let me organize this. As of January 2026, DeepSeek has four main generations. Each has different characteristics, so I'll explain them one by one.
Feature: The model that started the "reasoning revolution"
What's great:
- Scored an impressive 97.3% on math test (MATH-500)
- Shows its "thinking process" in <think> tags for transparency
- Open source, so anyone can modify and research it
Best for: Research, learning, customization
Feature: Improved stability for enterprise use
What's great:
- Fixed the "language mixing" issue from R1 (English and Chinese mixing)
- Improved reliability for tool integration (Function Calling)
- Can switch between "Thinking Mode" and "Chat Mode"
Best for: Enterprise system integration
Feature: Efficiency-focused latest model
What's great:
- Uses new DSA (DeepSeek Sparse Attention) technology
- Efficiently processes 128,000 tokens (about 100,000 characters)
- Same accuracy as V3.1 with over 50% reduced computation cost
Best for: Long document analysis, cost-conscious bulk processing
Feature: Next-gen model specialized in coding (rumored)
Expectations:
- Code generation surpassing Claude 3.5 Sonnet and OpenAI o3
- Ability to read entire projects and understand complex dependencies
- Reportedly achieved a "technical breakthrough"
Expected release: Mid-February 2026 (after Chinese New Year)

Hey Ran, I get that DeepSeek is great, but why is it so efficient? There must be some secret, right?
Sharp observation. There are two technologies supporting DeepSeek's efficiency. The first is mHC (Manifold-Constrained Hyper-Connections).
Let me use an analogy. AI has many "layers" inside, and information passes from layer to layer like a relay race. But with too many layers, the baton either gets amplified too much and "explodes" or gets too small and "vanishes".
I see! It's like having "volume control" so it stays stable no matter how complex it gets!
When you read a book, normal AI would calculate "the relationship between the 1st character on page 1 and every character on every page", then "the 2nd character on page 1 and every character on every page"... checking every combination.
What!? That sounds super hard! With a long book, the calculations would be insane...
Exactly. When text doubles, calculations quadruple (squared). But DSA dramatically reduces this by "selecting and focusing only on the important parts".
Ah! It's like studying for a test—"I can't read everything, so I'll focus on what's important"!

Hey, I heard you can run DeepSeek on your own computer—is that true?
Yes, it's true! This is one of the big trends in 2026—"Local LLM". By running AI on your own computer instead of relying on the cloud, you can use AI while protecting your privacy.
The key technology is "Quantization"—compressing AI to make it smaller. The "Dynamic 1-bit GGUF" format from "Unsloth" is particularly impressive. It can compress the DeepSeek-R1 671B model (normally over 350GB) down to 131GB-230GB.
🖥️ Example Setup for Running DeepSeek-R1 Locally
- GPU: NVIDIA RTX 4090 (24GB) × 2-4 cards
- RAM: 128GB-256GB high-speed DDR5
- Storage: 500GB+ SSD
*Speed is about 1-2 tokens/sec (slow, but the point is "it runs at home")
DeepSeek also has "distilled models"—lightweight versions where knowledge from large models is transferred to smaller ones. 7B or 14B models can run perfectly fine on a regular gaming PC.
💻 Example Ollama Command
With this single command, you can download and run the 14B model.

It's been all good news so far, but aren't there any downsides or dangers?
Sharp question... Actually, there are security concerns about DeepSeek. A report from the US CAISI (Center for AI Standards and Innovation) in September 2025 made headlines.
⚠️ Issue 1: Low Jailbreak Resistance
Reports indicate that DeepSeek responded to malicious prompts attempting to bypass "AI safety measures" 94% of the time (compared to 8% for US models). This means it could be more vulnerable to misuse.
⚠️ Issue 2: Thinking Process Exploitation
R1's feature of showing its thinking process could be used by attackers to find weaknesses. Since you can see when the AI is "trying to refuse," attackers could inject additional instructions to circumvent this.
The key is to "use different tools for different purposes". For personal use like writing or studying, it should be fine. But for enterprise systems handling customer data, careful consideration is needed.
I see. So "cheap and powerful" comes with trade-offs. Balance is key in everything!

🎯 Today's Key Points
- DeepSeek Shock: In January 2025, Chinese AI overturned Silicon Valley's assumptions, causing NVIDIA to lose $600 billion in a day
- Price Advantage: Maintains cost advantage of several to dozens of times compared to major AI models
- Tech Innovation: mHC (training stability) and DSA (efficient long-text processing) are the secrets to efficiency
- Local Use: Quantization technology enables running AI on home PCs
- Security: Use the right tool for the job. Personal use seems fine
As expected from you, Ran! Thanks for explaining all this complicated stuff so clearly!
O-oh... I just did what anyone would do...
Alright, that's it for today! See you next time!
See you next time. Take care!