DeepSeekがAI業界を激変させた!
技術革新からローカル活用まで徹底解説
中国発の超高性能AI「DeepSeek」の全貌を2人がわかりやすく紹介!
ラン!ラン!大変よ!最近ニュースで「DeepSeek」ってやつがすごいって話題になってるじゃない!NVIDIAの株価が一日で90兆円も消えたとか、中国のAIがアメリカを追い抜いたとか...
エテ先輩、落ち着いてください。確かに2025年1月の「DeepSeekショック」は、AI業界の歴史に残る出来事でしたね。2026年の今も、その影響は続いています。
そもそもDeepSeekって何なのよ?ChatGPTとかClaudeとは違うの?私にもわかるように説明しなさい!
わかりました。DeepSeek(深度求索)は、中国の杭州にある会社が開発した生成AIです。2025年1月にリリースされた「DeepSeek-R1」というモデルが、OpenAIのo1シリーズと同等の性能を持ちながら、当時の利用コストが100分の1以下という衝撃的な価格で提供されたんです。
なんですって!?同じ性能で100分の1以下の値段!?そりゃ大騒ぎになるわよね...

2025年1月27日、DeepSeek-R1がリリースされた直後、NVIDIAの株価が1日で約17〜18%暴落しました。時価総額にして約6,000億ドル、日本円で約90兆円が一瞬で消えた計算になります。
ちょっと待って、NVIDIAってあのグラフィックカードの会社よね?AIと何の関係があるの?
いい質問ですね。ChatGPTやClaudeのような生成AIを動かすには、膨大な計算が必要です。その計算を高速に処理できるのがNVIDIAのGPU(グラフィック処理ユニット)なんです。
※GPU:もともとはゲームの映像処理用でしたが、AIの計算にも向いていることがわかり、今ではAI開発に欠かせない部品になっています。
ふむふむ。つまり、AIを作るには高いグラボがたくさん必要だから、NVIDIAが儲かってたってこと?
その通りです!シリコンバレーでは「AIの性能を上げるには、とにかく高性能なGPUをたくさん買え」という考え方が主流でした。これを「スケーリング則」と呼んでいたんですが...
何があったの?
DeepSeekが「頭の良さ(アルゴリズム)で勝負すれば、GPUの数は少なくても高性能なAIが作れる」ことを証明してしまったんです。投資家たちは「あれ、GPUそんなに売れなくなるかも...」と思い、NVIDIAの株を一斉に売ったというわけです。
なるほどね...力任せじゃなくて、頭を使えば少ない資源でも勝てるってことを証明したわけか。なんか痛快ね!

で、実際どれくらい安いの?具体的な数字で教えてよ!
API利用料金で比較してみましょう。100万トークンあたりの料金です。各社の主力モデルを並べてみました。
※トークン:AIが文章を処理する際の最小単位です。日本語1文字がだいたい1〜2トークンくらいになります。
| モデル | 入力コスト | 出力コスト | 備考 |
|---|---|---|---|
| DeepSeek R1 | $0.55 | $1.68 | 推論特化 |
| DeepSeek V3.2 | $0.28 | $0.42 | 汎用チャット |
| OpenAI GPT-5 | $1.25 | $10.00 | 主力汎用モデル |
| OpenAI o3 | $2.00 | $8.00 | 推論特化 |
| Claude Sonnet 4.5 | $3.00 | $15.00 | Anthropic主力 |
| Claude Opus 4.5 | $5.00 | $25.00 | 最高性能 |
| Gemini 2.5 Pro | $1.25 | $10.00 | Google主力 |
| Gemini 3 Pro | $2.00 | $12.00 | 最新プレビュー |
※2026年1月調べ。単位:1Mトークンあたり(USD)。価格は変動する可能性があります。
ちょっと待って!Claude Opus 4.5が$5.00に対してDeepSeek V3.2が$0.28!? 入力で約18倍、出力で約60倍も違うじゃない!!
そうなんです。リリース当初ほどの価格差はなくなりましたが、今でもDeepSeekは主要モデルの中で圧倒的なコストパフォーマンスを誇っています。性能も数学やプログラミングのテストでは他社を上回ることがありますよ。
これはすごいわ!最高性能モデルと比べても数十倍安いってことでしょ?企業がコスト削減で乗り換えたくなる気持ちわかるわ!

ところで、さっきからR1とかV3.2とか色々出てくるけど、何がどう違うのよ?頭がこんがらがってきたわ...
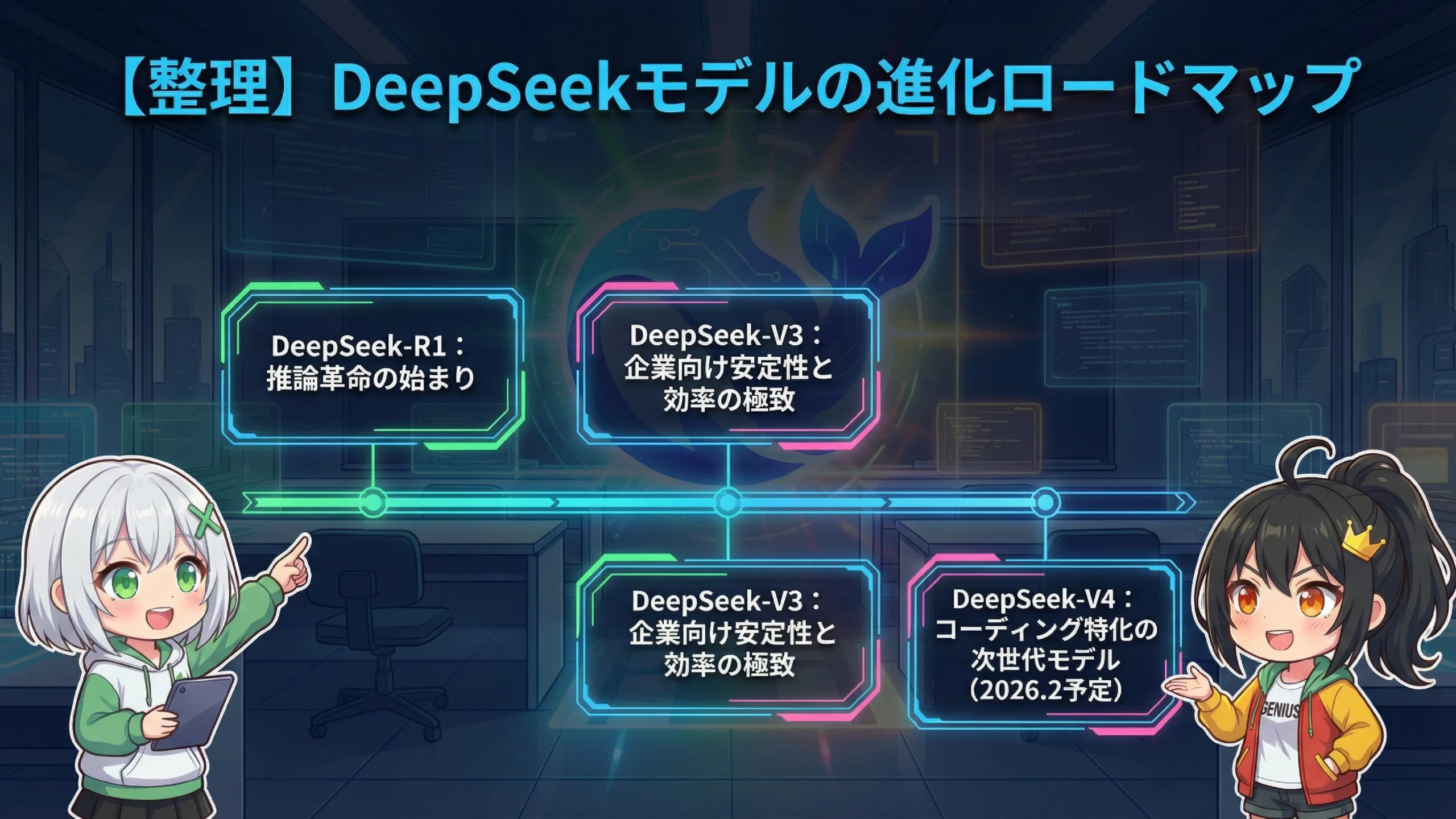
整理しますね。2026年1月現在、DeepSeekには主に4つの世代があります。それぞれ特徴が違うので、順番に説明しますね。
特徴:「推論革命の始まり」となったモデル
すごいところ:
- 数学テスト(MATH-500)で97.3%という驚異的なスコア
- 自分の「考えるプロセス」を<think>タグで見せてくれる透明性
- オープンソースなので誰でも改造・研究可能
向いている用途:研究、学習、カスタマイズしたい人向け
考えるプロセスを見せてくれるってどういうこと?
例えば「1+1は?」と聞くと、普通のAIは「2」とだけ答えます。でもR1は「まず1があって、もう1つの1を足すから...2だな」という思考過程も一緒に出力してくれるんです。これを「Chain-of-Thought(思考連鎖)」と呼びます。
へぇ!AIが何を考えてるかわかるのは面白いわね。数学の先生みたいに「途中式を見せなさい」って言われてるみたいね。
特徴:企業向けに安定性を高めたモデル
すごいところ:
- R1にあった「英語と中国語が混ざる問題」を解消
- ツール連携(Function Calling)の信頼性が向上
- 「じっくり考えるモード」と「サクッと答えるモード」を切り替え可能
向いている用途:企業のシステムに組み込みたい場合
特徴:効率化に特化した最新モデル
すごいところ:
- DSA(DeepSeek Sparse Attention)という新技術を搭載
- 128,000トークン(約10万文字)の長文を効率的に処理
- V3.1と同じ精度で、計算コストを50%以上削減
向いている用途:長い文書の分析、コスト重視の大量処理
どんどん進化してるのね!で、次は何が来るの?
特徴:コーディングに特化した次世代モデル(噂段階)
期待されていること:
- プログラムのコード作成でClaude 3.5 SonnetやOpenAI o3を超える性能
- プロジェクト全体を読み込んで、複雑な依存関係を理解する能力
- 「技術的ブレイクスルー」があったとの情報も
リリース予定:2026年2月中旬(春節明け)頃と噂されています
V4は特にプログラマーの間で期待されています。もしリークされている情報が本当なら、コード作成の常識が変わるかもしれませんね。
これは目が離せないわね!春節明けが楽しみだわ!
ねえラン、DeepSeekがすごいのはわかったけど、なんでそんなに効率がいいの?何か秘密があるんでしょ?
鋭いですね。DeepSeekの効率の良さを支える技術が2つあります。1つ目がmHC(Manifold-Constrained Hyper-Connections)です。
マニフォールド・コンストレインド...なに?日本語で言って!
(やっぱりそうなりますよね...)では、たとえ話で説明しますね。
AIの中には「層」というものがたくさんあって、情報がバトンリレーのように層から層へ伝わっていきます。でも層が増えすぎると、バトンを渡すたびに情報が増幅されすぎて「爆発」したり、逆に小さくなりすぎて「消失」したりする問題がありました。
ふむふむ。伝言ゲームみたいに、途中で話が大きくなったり消えちゃったりするってこと?
まさにそんなイメージです!従来の方法だと64層くらいで限界でしたが、mHCは「バトンの大きさを常に一定に保つ仕組み」を入れることで、もっと深い層まで安定して情報を伝えられるようになりました。
なるほど!「音量調節機能」みたいなものがあるから、どれだけ複雑になっても安定してるってわけね!
そうです!この技術のおかげで、学習がより速く・安定して進むようになりました。ベンチマークテストでは、従来の43.8点から51.0点に向上したというデータもあります。
2つ目の技術も教えて!
2つ目はDSA(DeepSeek Sparse Attention)です。これは特に長い文章を処理するときに威力を発揮します。
スパース...アテンション?また横文字...
「スパース」は「まばらな」、「アテンション」は「注目」という意味です。例えを使いますね。
本を読むとき、普通のAIは「1ページ目の1文字目と、全ページの全文字の関係性」を計算して、「1ページ目の2文字目と、全ページの全文字の関係性」も計算して...という具合に、すべての組み合わせを調べていたんです。
えっ!?それって超大変じゃない!長い本だったら計算量がとんでもないことになりそう...
そうなんです。文章が2倍になると、計算量は4倍になる(二乗)という問題がありました。でもDSAは「重要そうな部分だけ選んで集中して読む」という方法で、これを大幅に削減しました。
あー!テスト勉強で「全部読むのは無理だから、重要なところだけ読む」みたいな感じね!
その例えは...まあ、近いかもしれません。でも人間の「ヤマ張り」と違って、DSAは「Lightning Indexer」という仕組みで本当に重要な部分を正確に見つけ出すので、精度は落ちないんですよ。
すごいじゃない!頭を使って効率よく処理するから、コストも半分以下になったってわけね!
ねえねえ、DeepSeekって自分のパソコンでも動かせるって聞いたんだけど本当?
はい、本当です!これが2026年の大きなトレンドの1つ、「ローカルLLM」ですね。クラウドに依存せず、自分のパソコンでAIを動かすことで、プライバシーを守りながらAIを使えるんです。
でも、DeepSeekって超巨大なAIなんでしょ?普通のパソコンで動くの?
そこで登場するのが「量子化」という技術です。簡単に言うと、AIの中身を「圧縮」してサイズを小さくする技術ですね。
特に「Unsloth」というツールが開発した「Dynamic 1-bit GGUF」という形式がすごいんです。DeepSeek-R1の671Bモデル(通常なら350GB以上必要)を、なんと131GB〜230GBまで圧縮できます。
131GBでも十分大きいんだけど...それって具体的にどんなパソコンなら動くの?
以下のような構成が目安になりますね:
🖥️ ローカルでDeepSeek-R1を動かすための構成例
- GPU:NVIDIA RTX 4090(24GB)×2〜4枚
- メモリ(RAM):128GB〜256GBの高速DDR5
- ストレージ:SSD 500GB以上
※速度は1〜2トークン/秒程度(遅いですが、「自宅で動く」ことが重要)
RTX 4090が4枚!?それゲーミングPCどころじゃないわよ!超ハイスペックじゃない!
まあ、フルサイズの671Bモデルを動かすにはそれくらい必要ですね。でも安心してください、もっと小さいモデルもあります。
DeepSeekには「蒸留モデル」という、大きなモデルの知識を小さなモデルに移した軽量版もあるんです。例えば7Bや14Bのモデルなら、普通のゲーミングPCでも十分動きますよ。
よかった!それなら私のパソコンでも試せそうね!
使うツールとしてはOllamaやLM Studioが人気ですね。どちらも初心者でも比較的簡単に使えます。プログラマーの方ならContinue.devという VS Code の拡張機能でコーディング支援として使うこともできますよ。
💻 Ollamaでの起動コマンド例
このコマンド1つで、14Bサイズのモデルをダウンロードして起動できます。

ここまでいい話ばっかりだけど、何かデメリットとか危険なところはないの?
鋭いですね...実は、DeepSeekにはセキュリティ面で懸念点があることも指摘されています。2025年9月に米国のCAISI(AI標準化センター)が発表した評価レポートが話題になりました。
どんな問題があるの?
主に2つの問題が指摘されています。
⚠️ 問題1:ジェイルブレイク(脱獄)耐性の低さ
悪意あるプロンプトで「AIの安全装置」を外そうとする攻撃に対して、DeepSeekは94%の確率で応答してしまったという報告があります(米国製モデルは8%)。つまり、悪用されやすい可能性があるということですね。
⚠️ 問題2:思考プロセスの逆利用
R1の特徴である「思考を見せてくれる機能」が、逆に攻撃者にとっての「弱点探し」に使われる恐れがあります。AIが「断ろうとしている」思考過程が見えてしまうため、それを回避する追加の指示を出されてしまうリスクがあるのです。
うーん...じゃあ使わない方がいいの?
そこまで心配しなくても大丈夫ですよ。大切なのは「用途に応じて使い分ける」ことです。
例えば、個人で文章作成や勉強に使う分には問題ないでしょう。でも、企業が顧客データを直接扱うシステムにDeepSeekを組み込む場合は、慎重な検討が必要ですね。
なるほどね。「安くて高性能」には理由があるってことか。何事もバランスが大事ってことね!

ここまでの内容をまとめてみましょう。
🎯 今日のポイント
- DeepSeekショック:2025年1月、中国発のAIがシリコンバレーの常識を覆し、NVIDIAの株価が一日で90兆円消失
- 価格優位:主要AIモデルと比較して数倍〜数十倍のコスト優位性を維持
- 技術革新:mHC(学習の安定化)とDSA(効率的な長文処理)が効率化の秘密
- ローカル活用:量子化技術で自宅のPCでもAIを動かせる時代に
- セキュリティ:用途に応じた使い分けが大切。個人利用なら問題なさそう
いやー、今日は盛りだくさんだったわね!AI業界がこんなに激動してたなんて知らなかったわ!
2026年はまさにAIの転換期ですね。2月のV4リリースも楽しみですし、ローカルLLMの普及でAIがもっと身近になっていくと思います。
さすがランね!難しい話もわかりやすく教えてくれてありがとう!
そ、そんな...当然のことをしただけです...
それじゃあ、今日はここまで!また次回ね〜!
また次回お会いしましょう。お疲れ様でした!